During my discussions with customers I’ve sometimes heard some incorrect expectations and assumptions when people are defining their backup and recovery strategy. As a database and, in general, data centric person I think it is quite important to understand what the Point In Time Recovery (PITR) means and what Google Cloud SQL can do and what it cannot do. The information here is relevant for September 2022 when the post has been written.
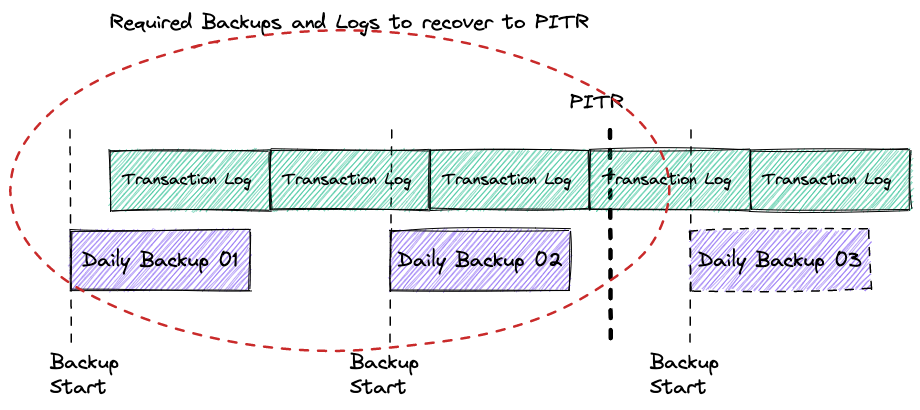
Let’s start from the point of time recovery and how it works. From the high level of view the PITR should provide the ability to restore and recover your data up to the last seconds defining a desirable point of time in the past to represent the consistent dataset at that moment.
To achieve that goal the database recovery uses a combination of backup and stored transaction logs. The transaction logs contain sequential records with all the changes applied to the database dataset. The logs have different names, such as binary log, Write-Ahead Logging (WAL) or Redo logs, but conceptually they are designed to store and apply information for recovery purposes. To recover the database instance should be restored from the latest suitable backup which was completed before the PITR and apply all the changes from the transaction logs starting from time when the backup had started and until the PITR time.
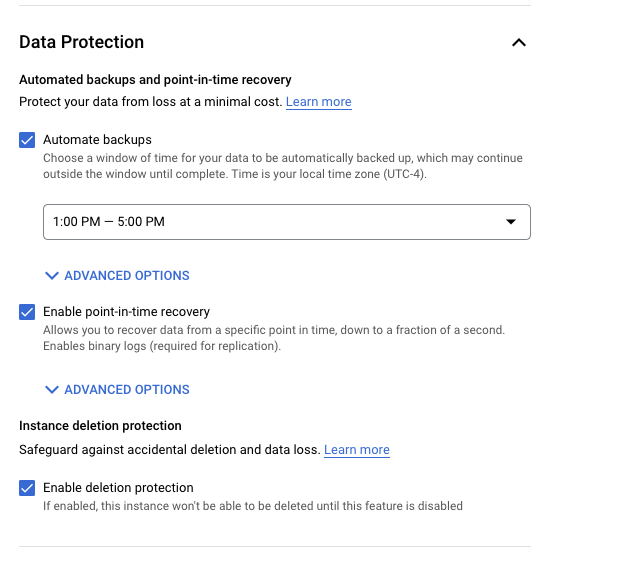
So, how does it work in Cloud SQL where the PITR is supported? First you have to enable the feature either when you create a database instance. It is not enabled by default.
Or after creation going to the backup properties.
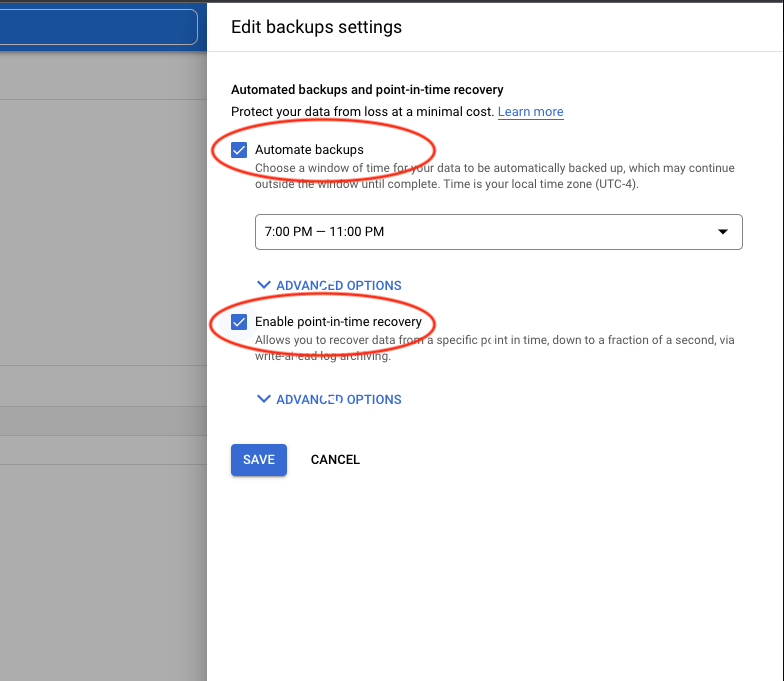
As soon as it is enabled it will start to take the daily automated backups and retain the transaction log for at least 1 day and up to 7 days. It means you should be able to recover your instance to any point of time for the last 7 days considering you have backup and the required transaction logs.
As I’ve mentioned above, to recover your instance to the desired point of time you have to have the backup taken prior to that point and transaction logs starting from time when the backup has started and up to the point of time.
Let’s say we have created a table with some important data at 1:40pm EDT (17:40 GMT)
CREATE TABLE test_tab_1 (id mediumint NOT NULL AUTO_INCREMENT, rnd_str CHAR(10), use_date datetime, PRIMARY KEY (id)); INSERT INTO test_tab_1 (rnd_str,use_date) VALUES (LEFT(UUID(), 8), sysdate()); INSERT INTO test_tab_1 (rnd_str,use_date) VALUES (LEFT(UUID(), 8), sysdate()); INSERT INTO test_tab_1 (rnd_str,use_date) VALUES (LEFT(UUID(), 8), sysdate()); INSERT INTO test_tab_1 (rnd_str,use_date) VALUES (LEFT(UUID(), 8), sysdate()); INSERT INTO test_tab_1 (rnd_str,use_date) VALUES (LEFT(UUID(), 8), sysdate()); commit; > SELECT * FROM test_tab_1 id|rnd_str |use_date | --+--------+-------------------+ 1|56ea4c19|2022-09-26 17:40:40| 2|5700593b|2022-09-26 17:40:41| 3|57163de1|2022-09-26 17:40:41| 4|572c567d|2022-09-26 17:40:41| 5|5742d7c4|2022-09-26 17:40:41|
Then somebody deleted the data around 1:50pm EDT.
> DELETE FROM test_tab_1 5 ROW(s) modified. > SELECT * FROM test_tab_1 id|rnd_str|use_date| --+-------+--------+ 0 ROW(s) fetched.
Now we have to recover the data. In the Cloud SQL console we click on our database instance and on the “Overview” page we click on “Clone” and choose “Clone from earlier point of time”.
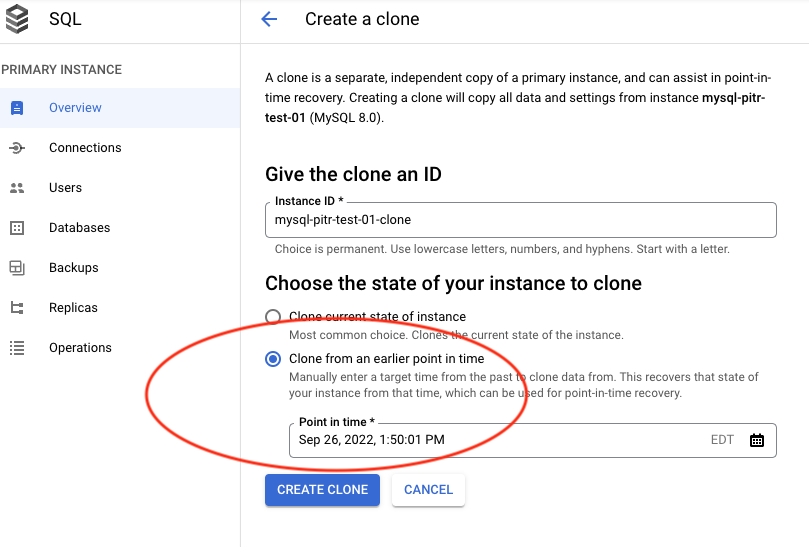
As soon as the clone is created you have a couple of choices. You can export the required data from the new clone and import them to the original instance. It would be probably the least disruptive way and would make sense if you want to recover only one of few tables keeping the rest untouched.
The second choice is to take a backup of the clone and restore it to the original instance. In this case all the data in the original instance will be replaced by the dataset state for point of time recovery. That way makes sense if you have a lot of interdependencies in your tables and you need a consistent dataset for a certain point of time.
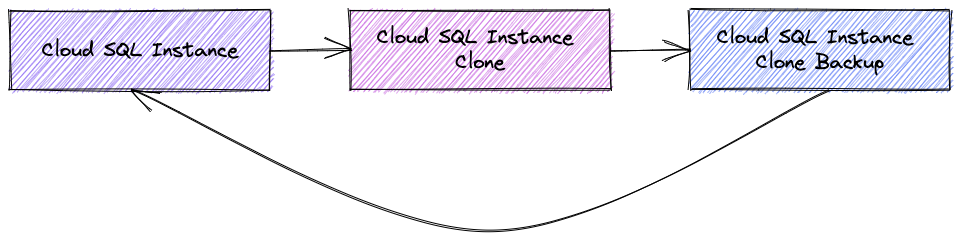
The process would require downtime since all the data should be copied over but after that we have the same IP, users and can use the data again.
> SELECT * FROM test_tab_1 id|rnd_str |use_date | --+--------+-------------------+ 1|56ea4c19|2022-09-26 17:40:40| 2|5700593b|2022-09-26 17:40:41| 3|57163de1|2022-09-26 17:40:41| 4|572c567d|2022-09-26 17:40:41| 5|5742d7c4|2022-09-26 17:40:41| 5 ROW(s) fetched.
That’s all useful and clear but let’s talk about disaster recovery. What would happen if your instance is in a single zone and the zone is going down. Or if your HA instance is going down along with the entire region. I know it is unlikely but we have to be prepared anyway. In that case you should be able to access your backups. It means you can restore your database to another instance in the DR region. But you will not be able to use point in time recovery since your logs are not accessible. For point in time recovery your original instance has to be up and running. That you need to keep in mind designing your backup strategy.
So, the original instance with the transaction logs should be up and accessible through console, API or CLI to perform the point of time recovery. You might have noticed that on the configuration page for your instance you can enable deletion protection. It is important because all your backups and transaction log are bound to your instance. It means if the instance is deleted then you can rely only on on-demand backups and exports and cannot use point in time recovery.
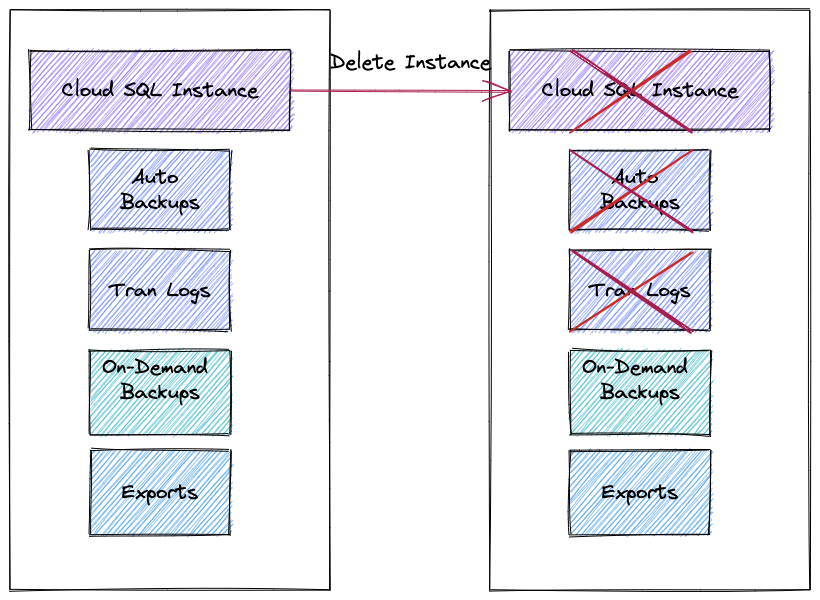
Here is a short summary for the Cloud SQL Point In Time Recovery.
- You need to enable automated backups and PITR on the instance
- You can use PITR only when the original instance up and running
- In case of a DR event if the original instance is down you can rely only on your backups and exports no point of time recovery
- If your instance is deleted you can use only on-demand backups and export and no point of time recovery
- Enable deletion protection during or after the instance creation
I hope it can help you to develop the correct backup and recovery strategy for your Cloud SQL and avoid surprises. Please let me know if I’ve made any mistakes or missed some important points.