During my discussions with customers I’ve sometimes heard some incorrect expectations and assumptions when people are defining their backup and recovery strategy. As a database and, in general, data centric person I think it is quite important to understand what the Point In Time Recovery (PITR) means and what Google Cloud SQL can do and what it cannot do. The information here is relevant for September 2022 when the post has been written.
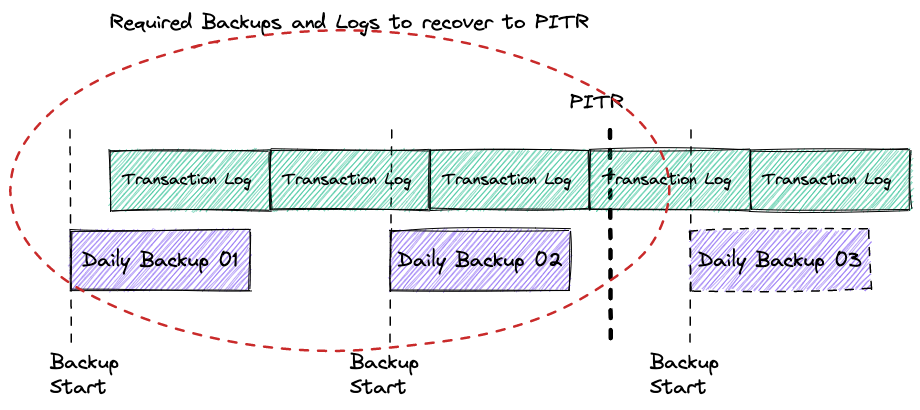
Let’s start from the point of time recovery and how it works. From the high level of view the PITR should provide the ability to restore and recover your data up to the last seconds defining a desirable point of time in the past to represent the consistent dataset at that moment.
To achieve that goal the database recovery uses a combination of backup and stored transaction logs. The transaction logs contain sequential records with all the changes applied to the database dataset. The logs have different names, such as binary log, Write-Ahead Logging (WAL) or Redo logs, but conceptually they are designed to store and apply information for recovery purposes. To recover the database instance should be restored from the latest suitable backup which was completed before the PITR and apply all the changes from the transaction logs starting from time when the backup had started and until the PITR time.
Continue reading “Google Cloud SQL Point In Time Recovery”