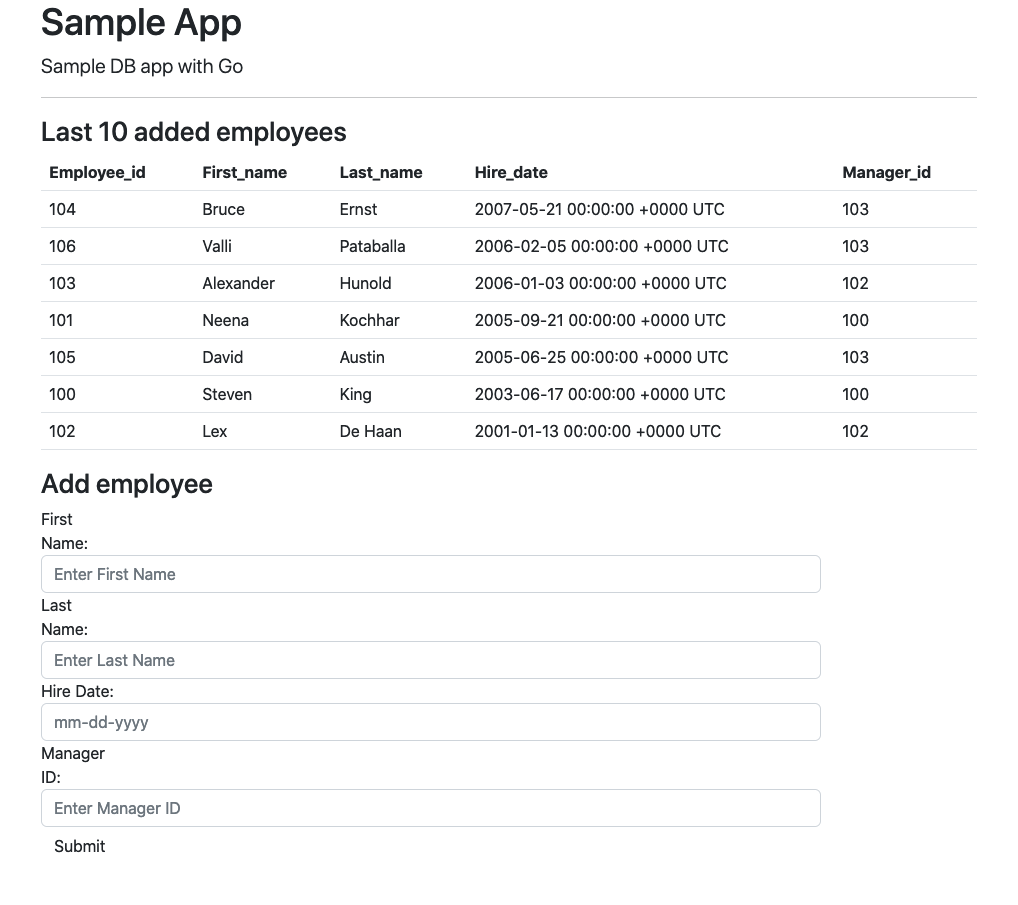
Most Oracle DBA are sufficiently educated about benefits using large memory pages for Oracle database SGA to reduce overhead and improve performance. If you want to read more about it you can start from that Oracle blog or read it from other multiple articles and blogs. Oracle is using parameter use_large_pages to direct behaviour of an Oracle instance during startup.
In the previous versions before 19c we had three possible values – “TRUE”, “FALSE and “ONLY”. Since Oracle 11.2.0.3 the “TRUE” meant that the instance will allocate as many hugepages as free available in the system and get the rest from the normal small pages. The “FALSE” would tell it to not use the hugepages at all and the “ONLY” would be able to start an instance only if sufficient number of free hugepages is available in the system to fit all SGA in it. The “TRUE” was default for all databases.
In the 19c version we got one more value – “AUTO_ONLY” and now it is the default value for Exadata systems running Oracle Database 19c. The description in documentation is not totally clear and sounds very similar to the description of “ONLY” value. Here is an excerpt from the documentation:
“It specifies that, during startup, the instance will calculate and request the number of large pages it requires. If the operating system can fulfill this request, then the instance will start successfully. If the operating system cannot fulfill this request, then the instance will fail to start.”
Let me show you how it works. Here is my sandbox with a 19c database and no hugepages is configured on the box by default.
Continue reading “Linux Hugepages and AUTO_ONLY in Oracle 19c.”