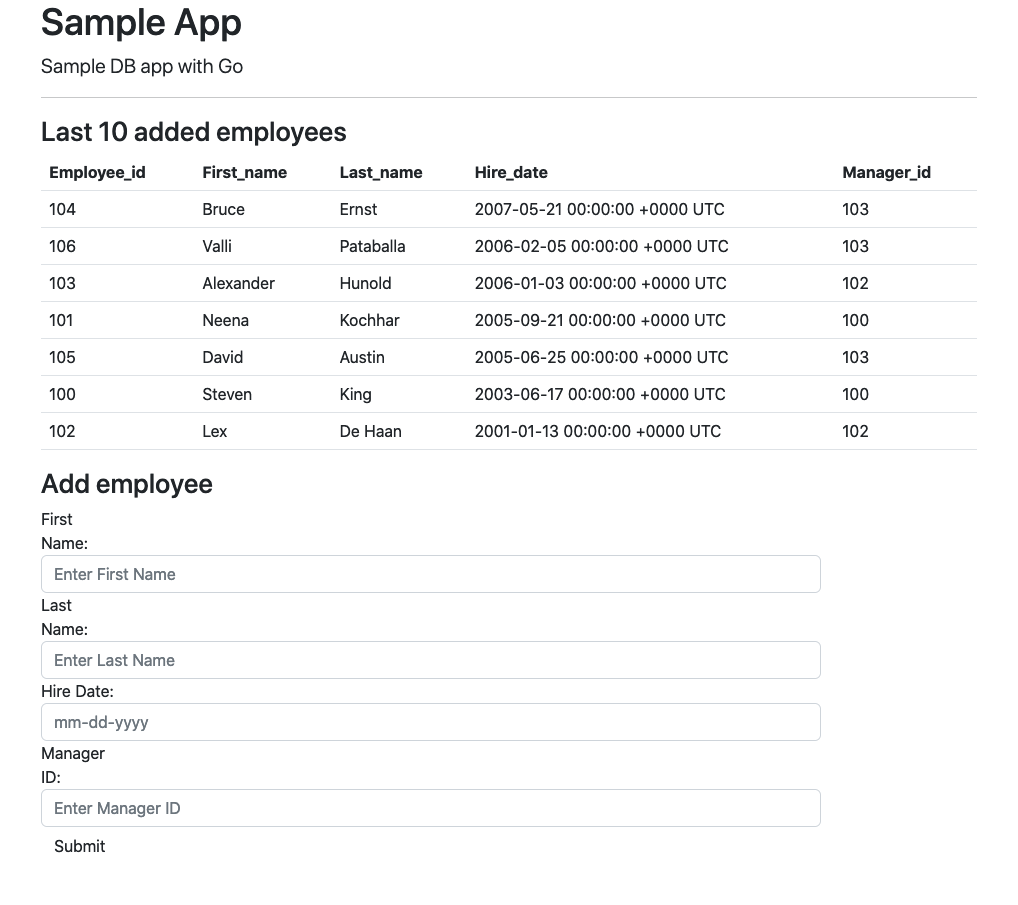
Oracle Linux 7 was released in 2014 and the system is close to its sunset. The premier support for the system will be wrapped up by July 2024 and it is time to think about moving forward. All the new systems, as I can see, are using version 8 and some even version 9. So it is time for an upgrade. And when we speak about upgrading we usually have two options – in-place and out-of-place. The in-place upgrade modifies the system on the same box keeping all the users data intact and the second approach is more like a migration when you move all your app stack and data to a new box with a new version of the OS. So, how difficult is the in-place upgrade and when it makes sense?
Continue reading “Oracle Linux in-place upgrade. Good, bad and the cloud. #JoelKallmanDay”