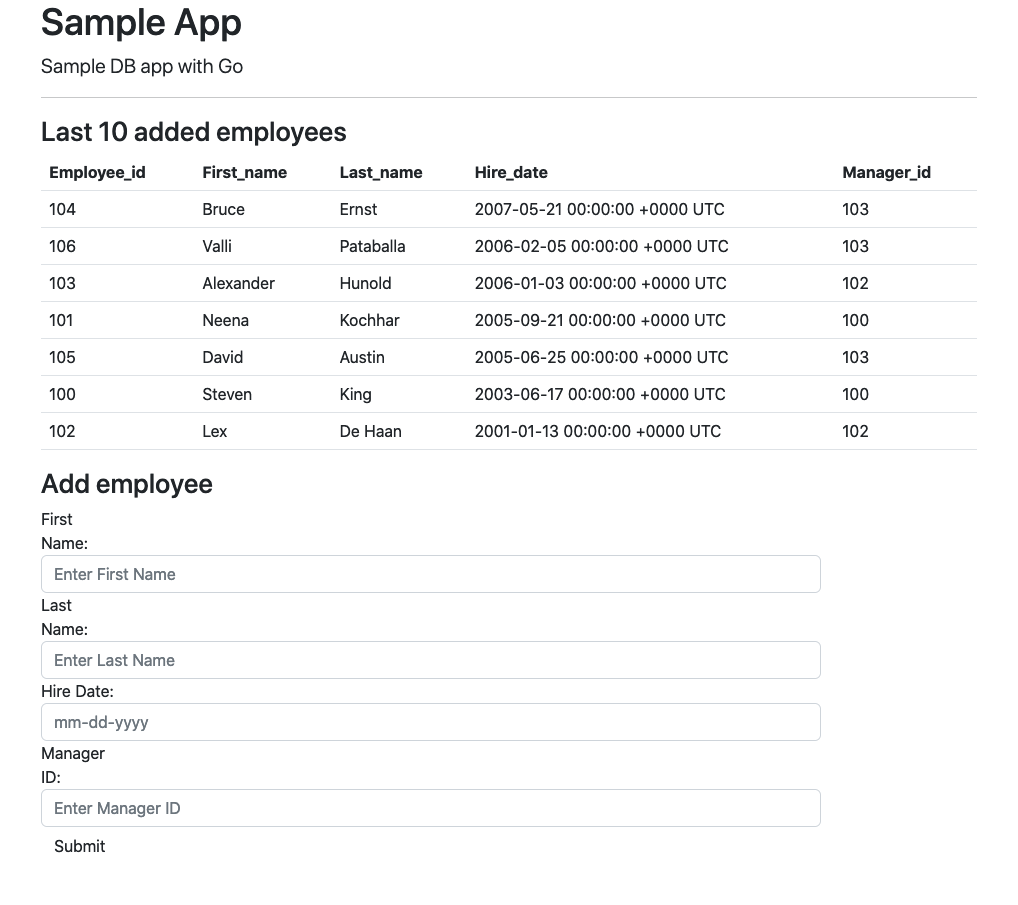
Yes, this is one more sample app as there are probably thousands already on the internet. We have tons of sample apps from different vendors with various types of licenses available on different repositories. Nevertheless sometimes I struggle to find exactly what I need – a simple app with a database backend which can work with Oracle Autonomous databases and optionally with Postgres backend. In my everyday life I primarily use Go as a programming language and I would like to have such an app written using that language. So, eventually I gave up and created my own application with a simple frontend and two (as for now) options for backend databases – Oracle and Postgres.
Continue reading “Sample Go application with database backend”