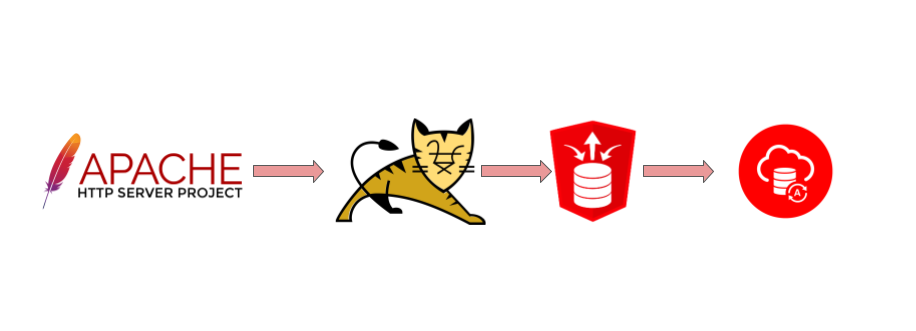
In one of my recent blogs I’ve described how you can use Nginx as a reverse proxy to assign your custom domain name to the Oracle Apex on Autonomous database. But you still use the default ORDS managed by Oracle. What if you want to change some ORDS parameters? For example you might decide to change the “low” type of connection to “high” or “medium”. In this post I will describe how to install your custom ORDS to work with Autonomous databases in standalone mode, using only Tomcat and Apache http server with Tomcat as the frontend.
Continue reading “Oracle Apex on Autonomous with custom ORDS”