In one of my recent blogs I’ve described how you can use Nginx as a reverse proxy to assign your custom domain name to the Oracle Apex on Autonomous database. But you still use the default ORDS managed by Oracle. What if you want to change some ORDS parameters? For example you might decide to change the “low” type of connection to “high” or “medium”. In this post I will describe how to install your custom ORDS to work with Autonomous databases in standalone mode, using only Tomcat and Apache http server with Tomcat as the frontend.
Oracle Linux 7 was released in 2014 and the system is close to its sunset. The premier support for the system will be wrapped up by July 2024 and it is time to think about moving forward. All the new systems, as I can see, are using version 8 and some even version 9. So it is time for an upgrade. And when we speak about upgrading we usually have two options – in-place and out-of-place. The in-place upgrade modifies the system on the same box keeping all the users data intact and the second approach is more like a migration when you move all your app stack and data to a new box with a new version of the OS. So, how difficult is the in-place upgrade and when it makes sense?
During my discussions with customers I’ve sometimes heard some incorrect expectations and assumptions when people are defining their backup and recovery strategy. As a database and, in general, data centric person I think it is quite important to understand what the Point In Time Recovery (PITR) means and what Google Cloud SQL can do and what it cannot do. The information here is relevant for September 2022 when the post has been written.
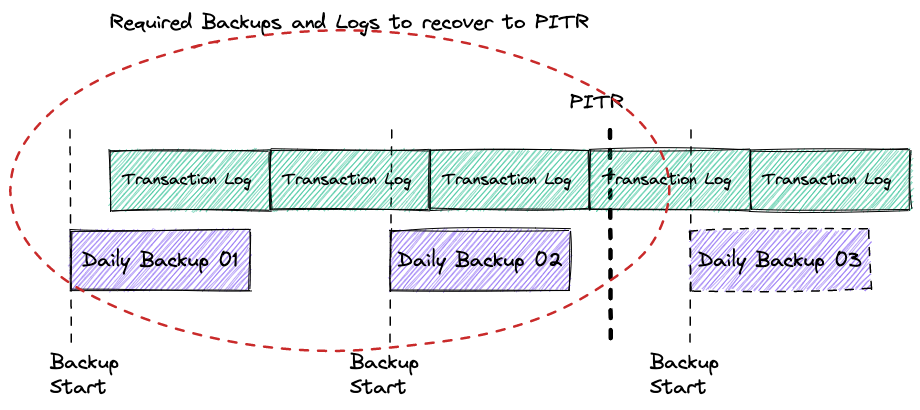
Let’s start from the point of time recovery and how it works. From the high level of view the PITR should provide the ability to restore and recover your data up to the last seconds defining a desirable point of time in the past to represent the consistent dataset at that moment.
To achieve that goal the database recovery uses a combination of backup and stored transaction logs. The transaction logs contain sequential records with all the changes applied to the database dataset. The logs have different names, such as binary log, Write-Ahead Logging (WAL) or Redo logs, but conceptually they are designed to store and apply information for recovery purposes. To recover the database instance should be restored from the latest suitable backup which was completed before the PITR and apply all the changes from the transaction logs starting from time when the backup had started and until the PITR time.
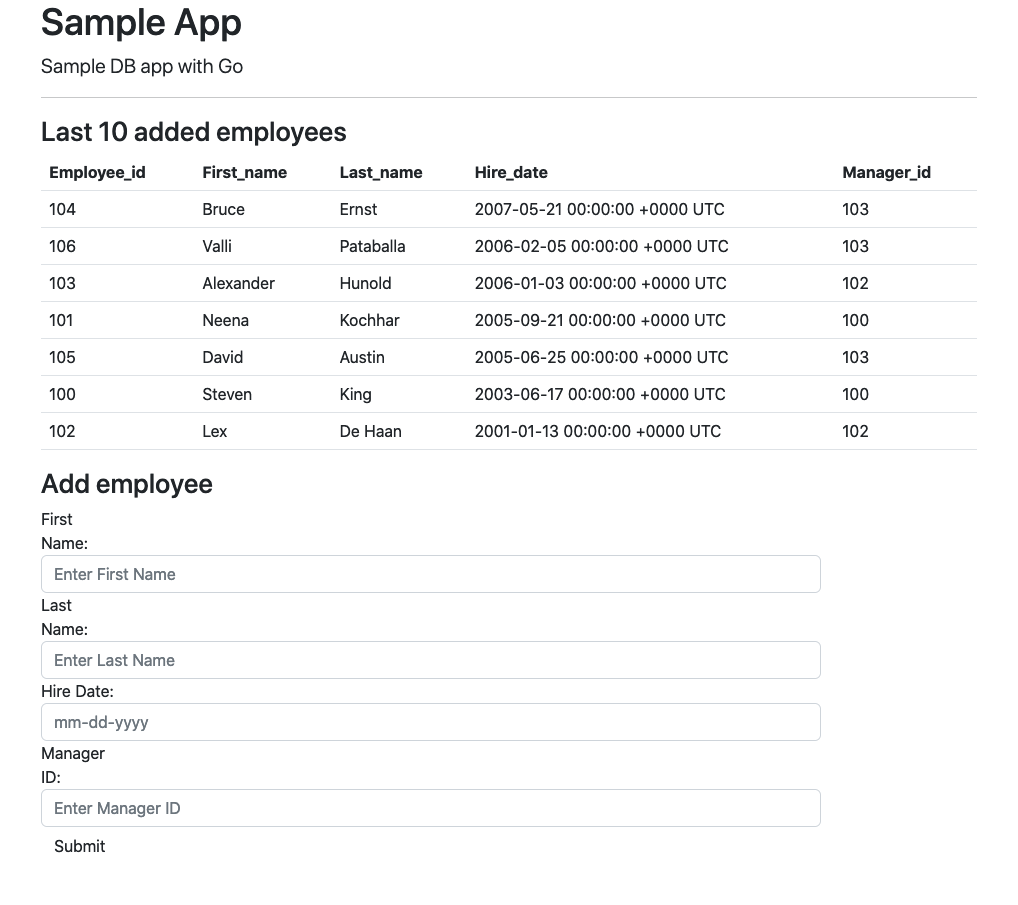
Yes, this is one more sample app as there are probably thousands already on the internet. We have tons of sample apps from different vendors with various types of licenses available on different repositories. Nevertheless sometimes I struggle to find exactly what I need – a simple app with a database backend which can work with Oracle Autonomous databases and optionally with Postgres backend. In my everyday life I primarily use Go as a programming language and I would like to have such an app written using that language. So, eventually I gave up and created my own application with a simple frontend and two (as for now) options for backend databases – Oracle and Postgres.
If you have an Apex app on top of your Oracle Autonomous database you have the application URL like https://m5c5hpup7eqqydh-glebatp01.adb.us-ashburn-1.oraclecloudapps.com/ords/r/covid/covid-ontario/covid_ontario. This is already better than it used to be before and have a friendly path in the URL but what if you want to use your own domain address and custom URL? This blog is about how to set it up using reverse proxy. The way with a custom ORDS is a subject for another post.
So, you have your own domain registered in DNS, for example apex.gleb.ca and an application like I’ve listed above. What you want to do is to make the application URL as https://www.apex.gleb.ca/covid/ . What we are going to use is a virtual machine with a Nginx web server serving as a reverse proxy to your Apex application created on the Oracle Autonomous database.
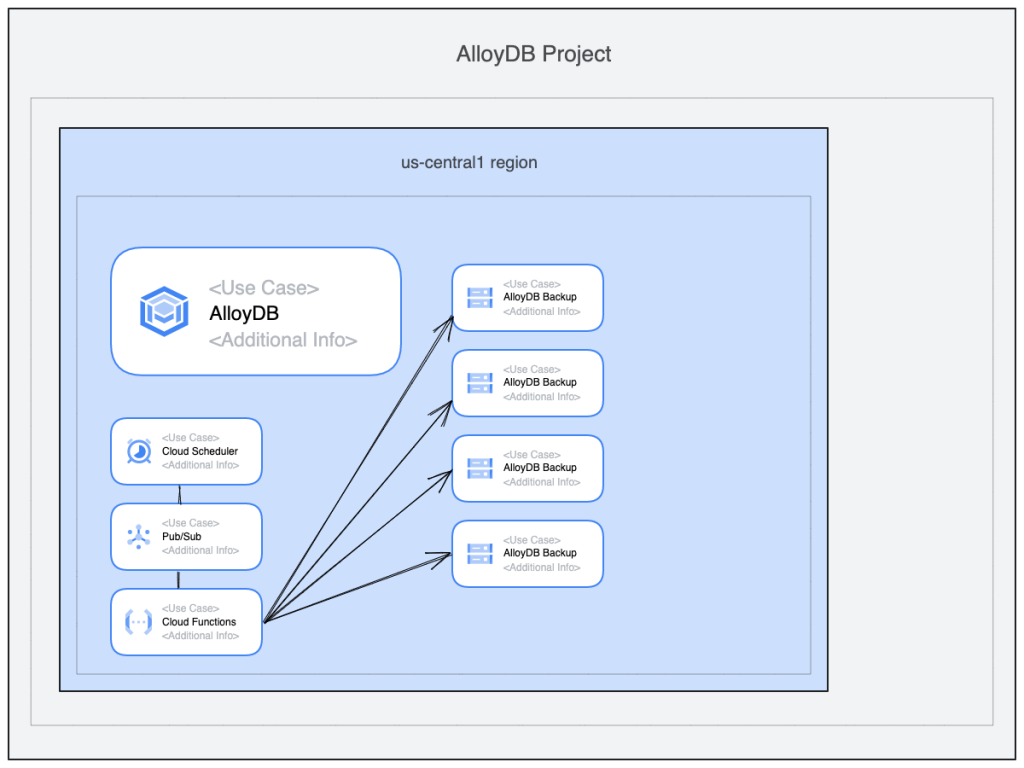
The post is about backup management for AlloyDB. It might be useful for the time when it is written but, probably, will be obsolete very soon when tools and API for the service will mature. A couple of words about AlloyDB backups and how they are created. The backups are quite different from the default backups for Cloud SQL for example. As we know in Cloud SQL all the backups are bound to the instance. What it means is when the instance is deleted then all the backups disappear along with the instance. It makes sense if the backups behind the scenes are storage snapshots from the databases. But in AlloyDB all the backups are decoupled from the cluster and exist by themselves. If you delete a cluster the backups stay. I think it is a way better approach because it provides a better way to protect from some mistakes when an instance is deleted before making a clone or exporting the data. As for now you can see all the backups for existing and deleted instances using the “backups” tab in the console, gcloud utility or listing using GCP REST API.
The GCP Config Connector (CC) is a Kubernetes add-on which allows you to create, change or delete cloud resources outside your cluster. It can deploy various GCP resources such as storage, databases, network and others representing them as a set of Kubernetes resources. It helps with a unified approach for deployment using Kubernetes to deploy the full stack for your application. The resources can be deployed by kubectl, helm or any CD (Continuous Deployment) tool you use in the organization.
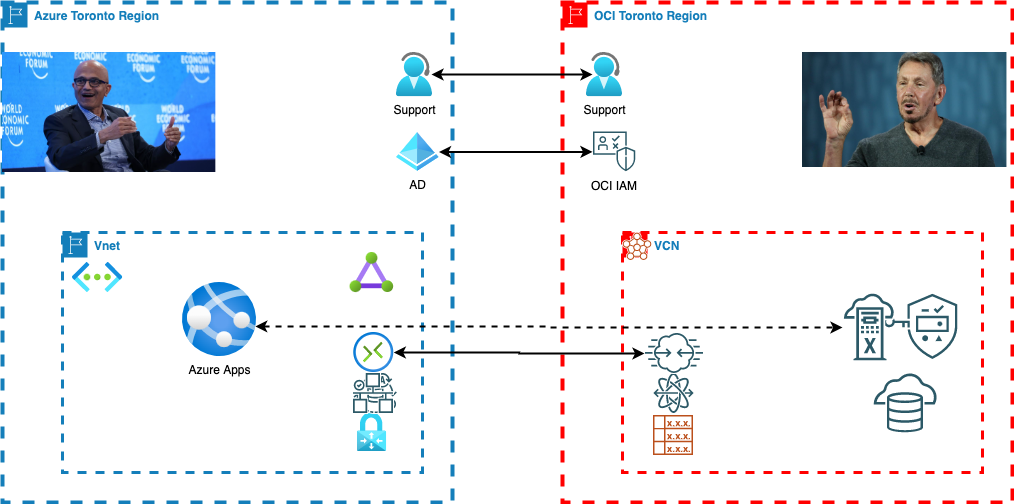
Recently Oracle and Microsoft announced availability of their new service – Oracle Database Service for Azure. It raises the level of integration and interoperability between Oracle Cloud and Microsoft Azure. With the new service Microsoft’s customers are able to create and manage Oracle databases created in Oracle cloud and use them for applications located in Azure. That sounds great and moves us one step closer to a real multi-cloud environment. Before proceeding, let me clarify what I mean as the “real” multi-cloud. I mean an environment where different pieces of the same IT service are located in different clouds working as a whole.
Earlier this year Oracle announced support for MongoDB API on the Oracle Autonomous database family. It has been recognized as a huge milestone by Forbes and multiple other analysts, technical and market experts. In my opinion it was logical and fully predicted one more step to the main idea of “Converged Database”. I didn’t coin that term – Oracle was using it for two or three years as of now. The main idea is to create a fully managed database platform supporting the most of APIs and interfaces and put the data together under the Oracle Autonomous Database umbrella. Here I will try to look inside and understand what it is, how it works, what is supported and what is not.
The blog was supposed to be a small how-to but it has grown to a bigger one and hopefully might help to avoid some minor problems while exporting data from an Autonomous Database (ADB) in Oracle Cloud (OCI). It is about exporting data to the Oracle DataPump format to move data to another database or as a logical “backup”.
Oracle documentation provides sufficient information but I find it more and more difficult to navigate considering the number of options and flavours for Oracle databases. There are some new ways and tools around Oracle OCI ATP which can help in some cases. If you want you can jump directly to the end to read the summary.